




یادگیری ماشین (Machine Learning) مفهوم جدید نیست. ایدهی اصلی آن یعنی اینکه «کامپیوترها بتوانند بدون برنامهنویسی، مستقیم از تجربه بیاموزند» اولین بار در دهه ۱۹۵۰ مطرح شد. آرتور ساموئل، یکی از چهرههای پیشگام این حوزه، برنامهای ساخت که با هر بار بازی چکرز، عملکردش بهبود مییافت. با این حال، یادگیری ماشین تا مدتها در حد یک نظریه باقی ماند.
نبود داده کافی و محدودیت توان پردازشی سیستمها، از موانع اصلی بودند. تحول واقعی زمانی رخ داد که دسترسی به دادههای عظیم (مانند اطلاعات شبکههای اجتماعی، تصاویر، صداها و خریدهای آنلاین) امکانپذیر شد و سختافزارها نیز به سطحی از قدرت رسیدند که بتوانند این دادهها را پردازش کنند.
در این نقطه، یادگیری ماشین از یک مفهوم تئوری به یکی از کلیدیترین ابزارهای هوش مصنوعی تبدیل شد. امروزه، از تشخیص چهره در گوشیهای هوشمند گرفته تا پیشنهادهای گوگل و شناسایی رفتارهای مشکوک بانکی، همگی حاصل پیشرفتهای چشمگیر در یادگیری ماشین است.
(در صورت علاقمند بودن به حوزه هوش مصنوعی، مطالعه مقاله «هوش مصنوعی چیست و چه کاربردی دارد؟» توصیه میشود.)
یادگیری ماشین مسیری گامبهگام و ساختاریافته دارد. برای کسی که تازه وارد این حوزه میشود، مهم است بداند که قرار نیست از همان ابتدا وارد کدنویسیهای پیچیده شود. یادگیری این مهارت شبیه یادگیری رانندگی است: ابتدا باید با ابزارها و مفاهیم آشنا شد، سپس به سراغ اجرای عملی رفت.
در سطح مقدماتی، مفاهیم پایهای مانند «داده چیست»، «ویژگیها (Features) چه هستند»، «الگوریتم چیست» و تفاوت میان یادگیری نظارت شده (Supervised) و بدون نظارت (Unsupervised) مطرح میشود. به طور مثال، در یادگیری نظارت شده، شما به الگوریتم نشان میدهید کدام عکس متعلق به گربه و کدام به سگ است، تا سیستم با الگوها آشنا شود و بتواند بهتنهایی آنها را تشخیص دهد.
با ورود به مراحل میانی و پیشرفته، سراغ الگوریتمهایی مانند درخت تصمیم (Decision Tree)، جنگل تصادفی (Random Forest)، شبکههای عصبی (Neural Networks) و یادگیری عمیق (Deep Learning) میروید. در این مراحل، معمولاً از زبان برنامهنویسی Python و کتابخانههایی مانند Scikit-learn، TensorFlow یا PyTorch استفاده میشود.
نکته مهم این است که یادگیری ماشین فقط به مطالعه تئوری محدود نمیشود؛ بلکه نیاز به تمرین عملی و انجام پروژههای واقعی دارد. مثلاً میتوانید سیستمی برای شناسایی ایمیلهای اسپم بسازید یا مدلی طراحی کنید که قیمت خانهها را پیشبینی کند. اگر مسیر آموزش را درست طی کنید، حتی بدون دانش عمیق ریاضی نیز میتوانید در این حوزه پیشرفت کنید؛ مهم پشتکار و تمرین مداوم است.

یادگیری ماشین به چند دسته اصلی تقسیم میشود که هرکدام برای حل نوع خاصی از مسائل طراحی شدهاند. آشنایی با این روشها کمک میکند تا بتوانید بهترین رویکرد را برای تحلیل دادهها انتخاب کنید.
در این روش، الگوریتم با دادههایی آموزش میبیند که خروجی آنها مشخص است. مانند آموزش دادن به کودکی که به او میگوییم: «این عکس گربه است، و دیگری سگ»، و سپس از او انتظار داریم در آینده عکسهای جدید را خودش تشخیص دهد.
به طور مثال: شناسایی ایمیلهای اسپم، پیشبینی قیمت خانه، تشخیص بیماری از روی عکس رادیولوژی.
در این شیوه، دادهها فاقد برچسب هستند و الگوریتم باید به تنهایی الگوها و ساختارها را در دادهها کشف کند. تصور کنید گروهی از افراد را بدون هیچ اطلاعات قبلی مشاهده میکنید و سعی دارید بفهمید چه کسانی شبیه به هماند.
به طور مثال: دستهبندی مشتریان برای بازاریابی هدفمند، فشردهسازی دادهها، کشف تقلبهای غیرمعمول.
ترکیبی از دو روش بالا است؛ یعنی بخشی از دادهها برچسب دارند و بخش دیگر ندارند. این روش زمانی مفید است که برچسبگذاری کامل دادهها هزینهبر یا زمانبر باشد.
به طور مثال شناسایی چهرهها در تصاویری که فقط بعضی از آنها نامگذاری شدهاند
در این روش، الگوریتم در محیطی قرار میگیرد که با انجام اقدامات مختلف، پاداش یا تنبیه دریافت میکند و با تکرار، بهترین تصمیمها را برای رسیدن به هدف یاد میگیرد.
به طور مثال: آموزش ربات برای راه رفتن، بازیهایی مانند شطرنج یا Go، سیستمهای هوشمند کنترل ترافیک.

در دنیای یادگیری ماشین، الگوریتمها نقش موتور محرک سیستمهای هوشمند را ایفا میکنند. هر الگوریتم با هدف حل نوع خاصی از مسئله طراحی شده و عملکرد آن به نوع دادهها و هدف نهایی پروژه بستگی دارد. در ادامه، با برخی از پرکاربردترین الگوریتمهای یادگیری ماشین و نحوه عملکرد آنها آشنا میشویم:
یکی از سادهترین و پایهایترین الگوریتمها در یادگیری ماشین، رگرسیون خطی است. این الگوریتم برای پیشبینی مقادیر عددی کاربرد دارد. به عنوان مثال، میتوان از آن برای پیشبینی قیمت یک خانه بر اساس عواملی مانند متراژ و تعداد اتاقها استفاده کرد.
در رگرسیون خطی، الگوریتم سعی میکند یک خط مستقیم روی دادهها رسم کند، بهگونهای که اختلاف بین مقدارهای واقعی و خطای پیشبینیشده تا حد ممکن کم باشد. این خط در واقع نشاندهندهی رابطه تقریبی میان ویژگیها و خروجی است.
این الگوریتم شبیه یک بازی بله/خیر عمل میکند. با ساختن یک درخت تصمیم، دادهها را بهصورت مرحلهبهمرحله تقسیم میکند تا به نتیجه نهایی برسد.
مثال: آیا یک مشتری واجد شرایط دریافت وام هست یا نه؟ الگوریتم با بررسی عواملی مانند میزان درآمد، سابقه بانکی و نوع شغل، تصمیمگیری میکند.
الگوریتم K نزدیکترین همسایه (K-Nearest Neighbors) بر پایهی شباهت کار میکند. این الگوریتم با بررسی K دادهای که از نظر ویژگیها به ورودی جدید نزدیکترند، تصمیم میگیرد که برچسب نهایی چه باشد. مثلاً اگر بیشتر همسایههای نزدیک یک تصویر «گربه» باشند، آن تصویر جدید نیز به عنوان «گربه» شناخته میشود.
مثال: تشخیص الگو در تصاویر، طبقه بندی دادههای پزشکی.
الگوریتم ماشین بردار پشتیبان (SVM) تلاش میکند بهترین مرز ممکن را بین دو دسته از دادهها پیدا کند؛ مرزی که بیشترین فاصله را از نزدیکترین نقاط هر کلاس داشته باشد. این ویژگی باعث میشود SVM در جداسازی دادههایی با مرز مشخص بسیار دقیق عمل کند.
مثال: شناسایی ایمیلهای اسپم و غیر اسپم، یا تفکیک سلولهای سرطانی از غیرسرطانی در دادههای پزشکی.
الگوریتم جنگل تصادفی (Random Forest) از ترکیب چندین درخت تصمیم استفاده میکند که هرکدام به طور مستقل آموزش دیدهاند. سپس با رأی گیری بین خروجی این درختها، تصمیم نهایی گرفته میشود. این ساختار باعث کاهش خطا و افزایش دقت نسبت به استفاده از تنها یک درخت تصمیم میشود.
مثال: پیشبینی رفتار مشتریان، تشخیص نوع بیماری بر اساس علائم، یا تحلیل ریسک اعتباری.
الگوریتمهای شبکه عصبی مصنوعی با الهام از ساختار مغز انسان طراحی شدهاند و از مجموعهای از «نورونها» تشکیل میشوند که اطلاعات را در چندین لایه پردازش میکنند. این الگوریتمها بهویژه برای حل مسائل پیچیدهای که روابط غیرخطی زیادی دارند بسیار موثرند.
مثال: تشخیص چهره در تصاویر، ترجمه خودکار متون، تولید گفتار یا تصویر با هوش مصنوعی.
هر الگوریتم یادگیری ماشین مزایا و محدودیتهای خاص خود را دارد. انتخاب الگوریتم مناسب به نوع داده، هدف پروژه و منابع موجود بستگی دارد.
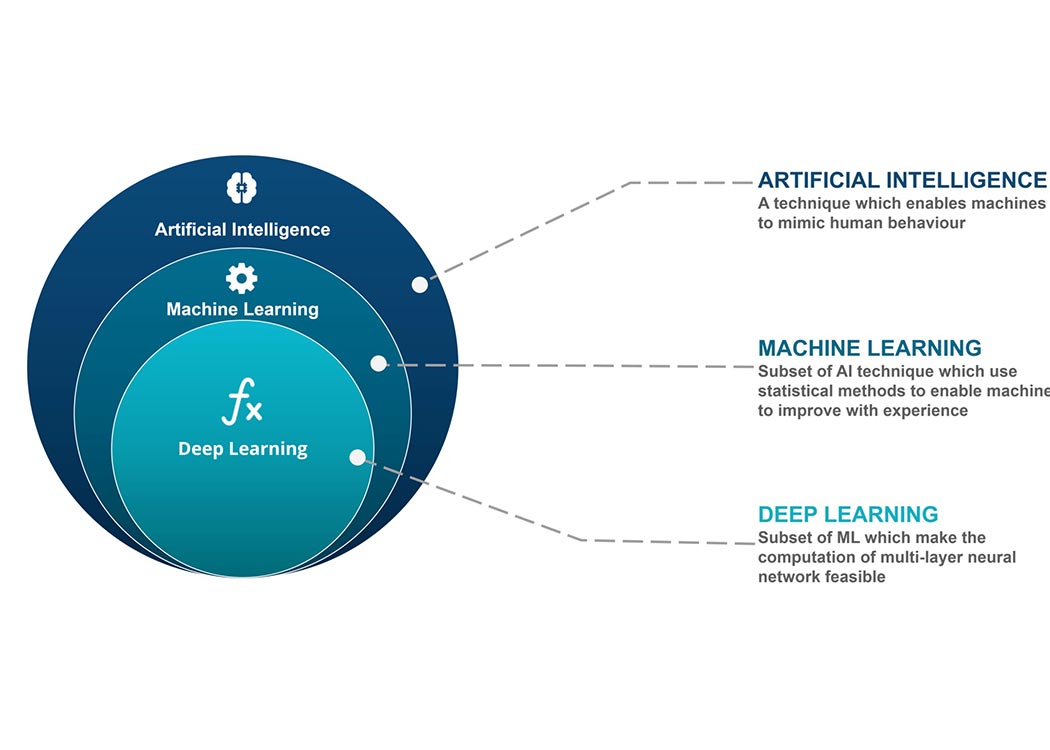
یادگیری ماشین، هوش مصنوعی و یادگیری عمیق سه مفهوم مرتبط اما متفاوت هستند. هوش مصنوعی (AI) به طور کلی به توسعه سیستمهایی اشاره دارد که قادرند مانند انسان فکر کرده و تصمیمگیری کنند.
یادگیری ماشین (Machine Learning) یکی از زیرمجموعههای هوش مصنوعی است که در آن سیستمها بدون نیاز به برنامهنویسی مستقیم، از دادهها یاد میگیرند. یادگیری عمیق (Deep Learning) هم شاخهای تخصصیتر از یادگیری ماشین است که از شبکههای عصبی پیشرفته برای حل مسائل پیچیده مانند تشخیص چهره، ترجمه زبان و رانندگی خودکار استفاده میکند.
بهطور خلاصه، یادگیری عمیق درون یادگیری ماشین و یادگیری ماشین درون هوش مصنوعی قرار دارد.
یادگیری ماشین را باید آموخت زیرا به ما کمک میکند تا با دادهها ارتباط برقرار کنیم، الگوها را کشف کنیم و تصمیمهای هوشمندانهتری بگیریم. در دنیای امروز که همه چیز به سرعت دیجیتال و داده محور میشود، توانایی استفاده از یادگیری ماشین یک مزیت رقابتی به شمار میآید.
با یادگیری این مهارت، میتوانید در زمینههایی مانند پزشکی (تشخیص بیماریها)، مالی (پیشبینی بازار)، بازاریابی (تحلیل رفتار مشتریان)، صنعت (نگهداری پیشبینیشده ماشینآلات)، آموزش (شخصیسازی مسیر یادگیری) و حتی در زندگی روزمره (مانند سیستمهای پیشنهاد دهنده فیلم و موسیقی) نقش مؤثری ایفا کنید.
از مزایای یادگیری ماشین میتوان به صرفهجویی در زمان، کاهش خطای انسانی، شناسایی الگوهای پنهان در دادهها و افزایش بهرهوری اشاره کرد. یادگیری ماشین مهارتی برای آینده است؛ آیندهای که هماکنون آغاز شده است.

یادگیری ماشین امروزه در مرکز تحول دیجیتال بسیاری از صنایع قرار گرفته و موجب شده تصمیم گیریها با سرعت، دقت و هوشمندی بیشتری انجام شوند. از تحلیل دادههای عظیم گرفته تا بهینه سازی فرایندها، این فناوری در بسیاری از حوزهها نقش کلیدی ایفا میکند. یکی از کاربردهای نوظهور و قابل توجه، ترکیب یادگیری ماشین با فناوریهای غوطهور نوینی مانند واقعیت ترکیبی (MR) است؛ جایی که مرز میان دنیای واقعی و دیجیتال به شکل بیسابقهای محو میشود.
واقعیت ترکیبی، که تلفیقی پیشرفته از واقعیت مجازی و افزوده محسوب میشود، امکان تعامل فعال میان کاربر و اشیای دیجیتال را در محیط فیزیکی فراهم میکند. در این میان، الگوریتمهای یادگیری ماشین با تحلیل رفتار کاربر، تشخیص صحنهها و پیش بینی نیازها، این تعامل را هوشمندتر و شخصی سازی شدهتر میکنند.
برای مثال، در صنایع تعمیر و نگهداری، سیستمهای مجهز به MR میتوانند با کمک یادگیری ماشین قطعات معیوب را تشخیص داده و راهنماییهای لازم را بهصورت زنده در دید کاربر نمایش دهند. در ادامه، نگاهی کاربردی به مهمترین حوزههایی میاندازیم که از این فناوری بهرهمند شدهاند:
اگر علاقهمند هستید بیشتر با این فناوری تحول آفرین آشنا شوید، پیشنهاد میکنیم به مقاله واقعیت ترکیبی چیست؟ مراجعه کنید، همچنین جهت آشنایی بیشتر با فناوری واقعیت مجازی، مطالعه مقاله واقعیت مجازی چیست؟ پیشنهاد میشود.
این فقط بخشی از کاربردهای گسترده یادگیری ماشین است. هر جا داده باشد، یادگیری ماشین میتواند ابزاری قدرتمند برای تصمیمسازی و پیشبینی باشد.

برای یادگیری ماشین، چه در ابتدای مسیر باشید و چه در سطح تخصصی، منابعی وجود دارند که مفاهیم را بهصورت دقیق و در عین حال قابل فهم آموزش میدهند. اگر تازهکار هستید، کتاب “Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow” نوشته Aurélien Géron انتخابی عالی است که با پروژههای عملی به آموزش میپردازد.
برای کسانی که به دنبال درک عمیقتر مفاهیم ریاضی و تئوریک هستند، کتاب “Pattern Recognition and Machine Learning” از Christopher Bishop یکی از منابع معتبر و جامع محسوب میشود.
همچنین، کتاب “Machine Learning Yearning” نوشته Andrew Ng با زبانی ساده و کاربردی به طراحی سیستمهای یادگیری ماشین میپردازد، بدون نیاز به درگیر شدن با جزئیات فنی برنامهنویسی. این منابع، ترکیبی متعادل از دانش نظری، تجربه عملی و دیدگاههای حرفهای ارائه میدهند.

اگر قصد دارید یادگیری ماشین را به صورت عملی یاد بگیرید ، پایتون بهترین زبان برای شروع است؛ هم ساده است و هم ابزارها و کتابخانههای قدرتمندی برای تحلیل داده و یادگیری ماشین دارد. در این مسیر، ابتدا از نصب ابزارهای لازم آغاز میکنیم و سپس مرحلهبهمرحله به سمت اجرای پروژههای واقعی پیش میرویم:
در قدم اول باید پایتون را بر روی سیستمتان نصب کنید (ترجیحاً نسخه ۳.۱۰ یا بالاتر). برای مدیریت راحتتر محیطهای کاری و کتابخانهها، پیشنهاد میشود از ابزار Anaconda استفاده کنید.
با نصب آن، میتوانید محیطهای مجزایی برای پروژههای مختلف بسازید و کتابخانههای موردنیاز را بهصورت کنترلشده نصب و مدیریت کنید. اگر به دنبال شروعی سادهتر و بدون نصب برنامهها هستید، میتوانید از Google Colab استفاده کنید. این ابزار تحت وب است؛ تنها به یک مرورگر نیاز دارد و امکان نوشتن، اجرا و اشتراکگذاری کدهای پایتون را به راحتی فراهم میکند.
کتابخانههای پایهای که در اکثر پروژههای یادگیری ماشین به آنها نیاز خواهید داشت، عبارتاند از:
NumPy: برای محاسبات عددی و کار با آرایهها
Pandas: برای خواندن، پردازش و تحلیل دادههای ساختار یافته
Matplotlib و Seaborn: برای ترسیم نمودار و تجسم دادهها
Scikit-learn: مجموعهای کامل از الگوریتمهای یادگیری ماشین و ابزارهای ارزیابی مدل
اگر بخواهید وارد حوزهی یادگیری عمیق (Deep Learning) شوید، کتابخانههایی مانند TensorFlow یا PyTorch نیز بسیار کاربردی و ضروری خواهند بود.
قبل از اجرای هر الگوریتم یادگیری ماشین، باید دادهها را بهدرستی آمادهسازی کنید. این مرحله شامل کارهایی مانند تمیز کردن دادهها، حذف یا جایگزینی مقادیر گمشده، نرمالسازی مقادیر عددی و دستهبندی متغیرهای متنی است. بهعنوان مثال، میتوانید با استفاده از کتابخانه pandas دادهها را از یک فایل CSV بخوانید و آنها را برای تحلیل آماده کنید.
با استفاده از کتابخانه Scikit-learn، میتوانید بهراحتی انواع الگوریتمهای یادگیری ماشین را پیادهسازی کنید. کافیست مدل مورد نظر (مثل رگرسیون خطی، درخت تصمیم، SVM، KNN و… ) را انتخاب کرده، آن را آموزش دهید و سپس برای پیشبینی از آن استفاده کنید
بعد از آموزش مدل، باید عملکرد آن را بر روی دادههای تست بررسی شود. این کار با معیارهایی مانند دقت (accuracy)، میانگین خطا (MAE)، یا ماتریس سردرگمی (confusion matrix) انجام میشود.
در نهایت میتوانید یک پروژه واقعی اجرا کنید؛ به طور مثال:
یادگیری ماشین با پایتون یکی از بهترین مسیرها برای ورود به دنیای هوش مصنوعی است. پایتون با کتابخانههای متنوع مانند scikit-learn، pandas، matplotlib و حتی کتابخانههای عمیقتر مانند TensorFlow و PyTorch، هم برای افراد مبتدی و هم برای حرفهایها ابزار فوقالعادهای است.

در دنیای یادگیری ماشین، ابزارها و فریمورکهای زیادی وجود دارند، اما برخی از آنها محبوبتر و پرکاربردتر هستند:
این ابزارها بسته به نیاز پروژه (ساده یا پیچیده، تحقیقاتی یا صنعتی) انتخاب میشوند.

یادگیری ماشین با وجود کاربردهای گستردهاش، در مسیر اجرا و پیادهسازی با موانعی روبهروست. در ادامه، مهمترین چالشها و راهکارها را بهطور خلاصه مرور میکنیم:

برای ورود به بازار کار در حوزه یادگیری ماشین، باید یک مسیر مشخص و مرحلهبهمرحله را طی کنید. ابتدا مفاهیم پایهای آمار، ریاضیات و برنامهنویسی (ترجیحاً با پایتون) را یاد بگیرید.
سپس به سراغ الگوریتمهای پایهای یادگیری ماشین؛ مانند رگرسیون، درخت تصمیم، KNN و SVM بروید و آنها را با کتابخانههایی مانند Scikit-learn تمرین کنید. بعد از آن، مفاهیم پیشرفتهتری مانند یادگیری عمیق، شبکههای عصبی، و کار با فریمورکهایی مانند TensorFlow یا PyTorch را یاد بگیرید.
شرکت در پروژههای عملی، رقابتهای Kaggle و ساخت یک نمونهکار (Portfolio) قوی، نقش کلیدی در جذب کارفرماها دارد. در نهایت، یادگیری مهارتهای مکمل مثل تحلیل داده، ارتباط با تیم، و درک نیازهای کسبوکار، مسیر شما را برای ورود به شغلهای پرتقاضا در این حوزه هموارتر میکند.

برای تقویت مهارتهای یادگیری ماشین، بهترین راه انجام پروژههای عملی و کاربردی است. در ادامه چند پروژه پیشنهادی را معرفی میکنیم:
شروع با پروژههای ساده و رفتن به سمت پروژههای پیچیدهتر میتواند به شما کمک کند تا مهارتهای خود را بهطور تدریجی و مؤثر ارتقا دهید.

آینده شغلی متخصصان یادگیری ماشین در ایران و جهان بسیار روشن و پرتقاضا است. در ایران، متوسط حقوق مهندسان یادگیری ماشین در تهران حدود ۲۲۰ میلیون تومان در ماه است که نسبت به بسیاری از مشاغل دیگر در کشور رقم بالایی محسوب میشود.
در سطح جهانی، بهویژه در ایالات متحده، متوسط حقوق سالانه برای مهندسان یادگیری ماشین حدود ۱۶۹٬۰۰۰ دلار است که این رقم در شرکتهای بزرگ فناوری میتواند به بیش از ۲۵۰٬۰۰۰ دلار نیز برسد.
این ارقام نشاندهنده ارزش بالای تخصص در این حوزه است. با توجه به رشد سریع فناوریهای هوش مصنوعی و یادگیری ماشین، تقاضا برای متخصصان این زمینهها در حال افزایش است و پیشبینی میشود که فرصتهای شغلی در این حوزه همچنان رو به رشد باشد.

یادگیری ماشین به عنوان قلب تپنده هوش مصنوعی شناخته میشود و نقش کلیدی در پیشرفت آن دارد. اگر هوش مصنوعی را تلاشی برای شبیهسازی رفتارهای انسانی بدانیم، یادگیری ماشین ابزاری است که این رفتارها را بدون نیاز به برنامهنویسی خط به خط ممکن میسازد.
با استفاده از الگوریتمها و دادهها، سیستمها میتوانند الگوها را تشخیص دهند، تصمیم بگیرند و عملکردشان را در طول زمان بهبود دهند. کاربردهایی مانند تشخیص چهره، ترجمه خودکار، دستیارهای صوتی و خودروهای خودران، همگی بر پایه یادگیری ماشین توسعه یافتهاند.
به طور خلاصه، یادگیری ماشین همان چیزی است که به هوش مصنوعی توانایی یادگیری از تجربه و تفکر واقعی میبخشد.

در جدول زیر، مقایسهای کاربردی بین زبانهای پرطرفدار در یادگیری ماشین آورده شده است تا با توجه به نیاز و تواناییتان، بهترین انتخاب را داشته باشید:
| زبان برنامهنویسی | مزایا | معایب | محبوبترین کتابخانهها | مناسب برای |
| Python | ساده و خوانا، جامعه بزرگ، کتابخانههای گسترده | سرعت نسبتاً پایین در اجرا | Scikit-learn، TensorFlow، PyTorch، Keras | مبتدی تا پیشرفته، تحقیقات و تولید |
| R | قدرتمند در تحلیل آماری و مصورسازی | کمتر مناسب برای پروژههای تولیدی | caret، randomForest، e1071 | تحلیلگران داده، آمارگرها |
| Java | سریع و پایدار، مناسب برای اپلیکیشنهای در مقیاس بالا | سینتکس نسبتاً پیچیدهتر | Weka، Deeplearning4j | پروژههای صنعتی و سازمانی |
| C++ | سرعت بسیار بالا، کنترل کامل بر حافظه | دشوار برای یادگیری و توسعه | dlib، Shark | کاربردهای بلادرنگ (Real-time) مثل رباتیک |
| Julia | سریع مثل C، ساده مثل Python، مناسب برای محاسبات عددی | جامعه کوچکتر، منابع آموزشی محدود | Flux.jl، MLJ.jl | پژوهشهای علمی و مهندسی |
| JavaScript (Node.js) | مناسب برای توسعه وب، اجرای ML در مرورگر | محدود در مقایسه با Python | TensorFlow.js, Brain.js | پروژههای مبتنی بر وب و اپهای تعاملی |
اگر اول راه هستید و میخواهید سریع وارد دنیای یادگیری ماشین شوید، پایتون بهترین انتخاب است. اما اگر به توسعه اپلیکیشنهای مقیاسپذیر فکر میکنید یا پروژهی خاصی در نظر دارید، میتوانید بسته به نیاز از زبانهای دیگر استفاده کنید.

در ادامه، منابع معتبر و کاربردی فارسی و انگلیسی برای یادگیری ماشین آورده شده است:

یادگیری ماشین فرآیندی است که طی آن سیستمها میتوانند بدون برنامهنویسی صریح، از دادهها الگو بگیرند و تصمیمگیری کنند.
بله، آشنایی اولیه با زبان برنامهنویسی Python بسیار اهمیت دارد؛ چرا که اغلب ابزارها و مثالها در این حوزه با این زبان توسعه داده میشوند.
یادگیری ماشین یکی از زیرشاخههای هوش مصنوعی است که تمرکز آن بر یادگیری از دادههاست، در حالیکه هوش مصنوعی دامنهای وسیعتر از مفاهیم و تکنیکها را در بر میگیرد.
بله، در صورت تسلط عملی به مفاهیم، اجرای پروژههای واقعی و آشنایی با ابزارهای کاربردی، امکان ورود به بازار کار، حتی بدون مدرک رسمی وجود دارد.
مدت زمان یادگیری بستگی به میزان تمرین و پشتکار شما دارد، اما با مطالعه منظم روزانه بین یک تا دو ساعت، میتوانید طی شش تا نه ماه به سطح قابل قبولی برسید.
















